Hallo Community,
wir haben hier bei der allgemeinen Einrichtung angefangen vermehrt über eine KI Suche zu diskutieren. Auch weil ich gerade mehrere Fragen dazu habe, möchte ich hier einen Beitrag nur um das Thema KI Suche erstellen.
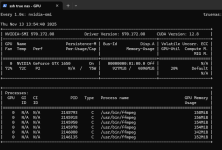
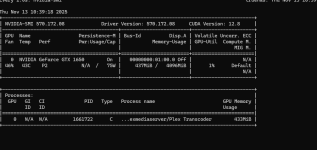
1. Ich habe "ViT-B-16-SigLIP2__webli" verwendet. bei 40.000 Fotos ging das auf der 920+ nach wenigen tagen. Aber die Ergebnisse sind nicht ausreichend.
2. Warum sind die Ergebnisse auf deutsch englisch so unterschiedlich?

3. Hier schreibt jemand vom RunPod. Wie verwendet das mit seinem Docker Immich auf seiner Synology? Bedeutet dass, dass man die KI auslagert?
4. Könnte ich die KI aufgaben auch für die 40.000 Fotos einmalig auf meinem MacBook Pro m4 KI Chip ausführen? Und dann alle einzelnen nur noch auf der Synology?
5. Wie konnte man den Docker optimieren? Mehr CPU und RAM vergeben? Hilft es das LOG vom Docker zu reduzieren? Angeblich soll das volllaufen können.
6. Gibt es ein PlugIn oder eine Möglichkeit, dass die Bilder über KI immer richtig rum gedreht werden? ich fotografier viel, nach vorne gebeugt, Dokumente, Tiere / Pflanzen von Oben. Da wird die Ausrichtung nicht richtig abgespeichert. Nun müsste ich all diese Fotos einzeln drehen. Das könnte doch einfach eine KI machen.
7. Welche KI Modelle kann man pauschal empfehlen?

8. Macht es überhaupt Sinn, ein nllb-Model zu verwenden? Weil es auch viele Wörter gibt, die Englisch sind und dann nicht so gut erkannt werden, oder?
9. Können wir hier mit den verschiedensten Modellen einige Teste machen? Oder jeder von euch sagt was er mit seinem Modell so feststellt? Da hätten wir eine schöne Stichprobe. =)
10. Was habt ihr optimiert oder eingestellt? Was verwendet ihr, was hilft euch? Oder geht eventuell noch mehr, als den meisten mit immich bewusst ist?
wir haben hier bei der allgemeinen Einrichtung angefangen vermehrt über eine KI Suche zu diskutieren. Auch weil ich gerade mehrere Fragen dazu habe, möchte ich hier einen Beitrag nur um das Thema KI Suche erstellen.
1. Ich habe "ViT-B-16-SigLIP2__webli" verwendet. bei 40.000 Fotos ging das auf der 920+ nach wenigen tagen. Aber die Ergebnisse sind nicht ausreichend.
2. Warum sind die Ergebnisse auf deutsch englisch so unterschiedlich?
3. Hier schreibt jemand vom RunPod. Wie verwendet das mit seinem Docker Immich auf seiner Synology? Bedeutet dass, dass man die KI auslagert?
4. Könnte ich die KI aufgaben auch für die 40.000 Fotos einmalig auf meinem MacBook Pro m4 KI Chip ausführen? Und dann alle einzelnen nur noch auf der Synology?
5. Wie konnte man den Docker optimieren? Mehr CPU und RAM vergeben? Hilft es das LOG vom Docker zu reduzieren? Angeblich soll das volllaufen können.
6. Gibt es ein PlugIn oder eine Möglichkeit, dass die Bilder über KI immer richtig rum gedreht werden? ich fotografier viel, nach vorne gebeugt, Dokumente, Tiere / Pflanzen von Oben. Da wird die Ausrichtung nicht richtig abgespeichert. Nun müsste ich all diese Fotos einzeln drehen. Das könnte doch einfach eine KI machen.
7. Welche KI Modelle kann man pauschal empfehlen?
8. Macht es überhaupt Sinn, ein nllb-Model zu verwenden? Weil es auch viele Wörter gibt, die Englisch sind und dann nicht so gut erkannt werden, oder?
9. Können wir hier mit den verschiedensten Modellen einige Teste machen? Oder jeder von euch sagt was er mit seinem Modell so feststellt? Da hätten wir eine schöne Stichprobe. =)
10. Was habt ihr optimiert oder eingestellt? Was verwendet ihr, was hilft euch? Oder geht eventuell noch mehr, als den meisten mit immich bewusst ist?