- Registriert
- 14. Okt. 2008
- Beiträge
- 211
- Reaktionspunkte
- 3
- Punkte
- 18
Nach 10 Jahren hat sich meine DS115 verabschiedet und die HDD ist in eine neue DS124 gewandert, als remote backup server. Die DS115 war nachts ausgeschaltet, hibernate Zeit 20 Minuten und trotzdem ist die HDD auf stolze Werte gekommen in der Zeit, fehlerfrei.
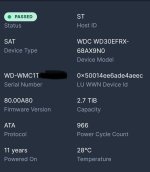
Your Western Digital Red WD30EFRX-68AX9N0 (3 TB NAS HDD) SMART report looks healthy overall, but it also shows that the drive is very old and heavily used. Here’s a clear breakdown.
 Health status
Health status
SMART overall result: PASSED
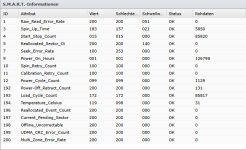
Reallocated sectors: 0
Pending sectors: 0
Uncorrectable sectors: 0
CRC errors: 0
Error log: empty
 This means the disk currently has no physical sector failures or communication problems.
This means the disk currently has no physical sector failures or communication problems.
 Age and usage
Age and usage
Important indicators:
Attribute Value Meaning
Power_On_Hours 41,255 h ~4.7 years powered on
Start_Stop_Count 46,199 Many spin-ups
Load_Cycle_Count 46,158 Head park/unpark cycles
Power_Cycle_Count 35,416 Many power cycles
Temperature 32 °C Good
Interpretation
41k hours is well into the later half of typical HDD life.
The start/stop count is very high, suggesting the disk has been frequently spun down/up (common in NAS or external setups).
Temperature is excellent, which helps longevity.
 SMART attribute review
SMART attribute review
The important failure predictors are all perfect:
Reallocated_Sector_Ct = 0
Current_Pending_Sector = 0
Offline_Uncorrectable = 0
Seek_Error_Rate = 0
These are the attributes that usually show problems months before a disk fails.
 Self-tests
Self-tests
You ran multiple tests:
Short tests: many → all passed
Extended tests: several → all passed
That means the disk surface scan found no read errors.
 Practical assessment
Practical assessment
Current state:
Healthy
Age:
 Old (≈5 years of runtime)
Old (≈5 years of runtime)
Risk level:
Moderate purely due to age
For WD Red drives:
Typical life: 30k–60k hours
You’re at 41k hours
 Recommendation
Recommendation
If this drive stores important data:
Keep good backups
Consider proactive replacement within 1–2 years
 Continue running monthly extended SMART tests
Continue running monthly extended SMART tests
If it's part of a NAS RAID:
It’s still safe to use, but I’d plan a replacement before 50–60k hours.
Summary
Category Status
Health Good
Surface No bad sectors
Temperature Good
Age Old
Recommendation Backup + plan replacement
Most people watch the wrong SMART values. The three attributes that actually predict HDD failure early (based on large studies like the ones by Google and Backblaze) are these:
 Reallocated Sector Count (ID 5)
Reallocated Sector Count (ID 5)
What it means:
The number of sectors that have failed and been replaced by spare sectors.
Why it matters:
Once a drive starts reallocating sectors, the failure rate rises sharply.
Typical interpretation:
Raw value Meaning
0 Perfect
1–10 Early warning
10–100 Disk deterioration
100+ High failure risk
Your drive:
Reallocated_Sector_Ct = 0
Excellent
 Current Pending Sector (ID 197)
Current Pending Sector (ID 197)
What it means:
Sectors that the drive could not read and is waiting to retry.
These are often the first sign of a dying disk.
Typical interpretation:
Raw value Meaning
0 Healthy
1–5 Early warning
5–50 Data loss likely soon
50+ Immediate replacement
Your drive:
Current_Pending_Sector = 0
Excellent
 Offline Uncorrectable (ID 198)
Offline Uncorrectable (ID 198)
What it means:
Sectors that could not be corrected even with error correction during background scans.
Typical interpretation:
Raw value Meaning
0 Healthy
>0 Serious reliability issue
Your drive:
Offline_Uncorrectable = 0
Excellent
Why these three matter most
Large-scale data center research showed:
~70–80% of HDD failures are preceded by one of these three values increasing.
Drives with even one reallocated sector fail several times more often than drives with none.
Other attributes like:
Raw_Read_Error_Rate
Seek_Error_Rate
Temperature
are much weaker predictors.
 The hidden risk in your report
The hidden risk in your report
Your drive’s only real risk factor is age:
Power_On_Hours: 41,255
≈ 4.7 years running
Typical HDD reliability curve:
0–20k hours → very safe
20–40k hours → normal
40–60k hours → rising failures
60k+ hours → high failure probability
You just entered the rising failure window.
One interesting thing in your SMART data
These values are very high:
Start_Stop_Count 46199
Power_Cycle_Count 35416
This suggests the disk was likely used in:
a NAS with aggressive spindown
an external USB enclosure
or a system that powers on/off often
Frequent spin-ups cause mechanical wear.
My honest verdict
Factor Status
Surface health Perfect
Bad sectors None
Error logs None
Temperature Good
Age Old
Spin cycles High
 Safe to keep using, but not a drive I'd trust without backups.
Safe to keep using, but not a drive I'd trust without backups.
Your Western Digital Red WD30EFRX-68AX9N0 (3 TB NAS HDD) SMART report looks healthy overall, but it also shows that the drive is very old and heavily used. Here’s a clear breakdown.
Health statusSMART overall result: PASSED
Reallocated sectors: 0
Pending sectors: 0
Uncorrectable sectors: 0
CRC errors: 0
Error log: empty
This means the disk currently has no physical sector failures or communication problems. Age and usageImportant indicators:
Attribute Value Meaning
Power_On_Hours 41,255 h ~4.7 years powered on
Start_Stop_Count 46,199 Many spin-ups
Load_Cycle_Count 46,158 Head park/unpark cycles
Power_Cycle_Count 35,416 Many power cycles
Temperature 32 °C Good
Interpretation
41k hours is well into the later half of typical HDD life.
The start/stop count is very high, suggesting the disk has been frequently spun down/up (common in NAS or external setups).
Temperature is excellent, which helps longevity.
SMART attribute reviewThe important failure predictors are all perfect:
Reallocated_Sector_Ct = 0
Current_Pending_Sector = 0
Offline_Uncorrectable = 0
Seek_Error_Rate = 0
These are the attributes that usually show problems months before a disk fails.
Self-testsYou ran multiple tests:
Short tests: many → all passed
Extended tests: several → all passed
That means the disk surface scan found no read errors. Practical assessmentCurrent state:
HealthyAge:
Old (≈5 years of runtime)Risk level:
Moderate purely due to ageFor WD Red drives:
Typical life: 30k–60k hours
You’re at 41k hours
RecommendationIf this drive stores important data:
Keep good backups Consider proactive replacement within 1–2 years Continue running monthly extended SMART testsIf it's part of a NAS RAID:
It’s still safe to use, but I’d plan a replacement before 50–60k hours.
SummaryCategory Status
Health
GoodSurface
No bad sectorsTemperature
GoodAge
OldRecommendation Backup + plan replacement
Most people watch the wrong SMART values. The three attributes that actually predict HDD failure early (based on large studies like the ones by Google and Backblaze) are these:
Reallocated Sector Count (ID 5)What it means:
The number of sectors that have failed and been replaced by spare sectors.
Why it matters:
Once a drive starts reallocating sectors, the failure rate rises sharply.
Typical interpretation:
Raw value Meaning
0 Perfect
1–10 Early warning
10–100 Disk deterioration
100+ High failure risk
Your drive:
Reallocated_Sector_Ct = 0
Excellent Current Pending Sector (ID 197)What it means:
Sectors that the drive could not read and is waiting to retry.
These are often the first sign of a dying disk.
Typical interpretation:
Raw value Meaning
0 Healthy
1–5 Early warning
5–50 Data loss likely soon
50+ Immediate replacement
Your drive:
Current_Pending_Sector = 0
Excellent Offline Uncorrectable (ID 198)What it means:
Sectors that could not be corrected even with error correction during background scans.
Typical interpretation:
Raw value Meaning
0 Healthy
>0 Serious reliability issue
Your drive:
Offline_Uncorrectable = 0
Excellent Why these three matter mostLarge-scale data center research showed:
~70–80% of HDD failures are preceded by one of these three values increasing.
Drives with even one reallocated sector fail several times more often than drives with none.
Other attributes like:
Raw_Read_Error_Rate
Seek_Error_Rate
Temperature
are much weaker predictors.
The hidden risk in your reportYour drive’s only real risk factor is age:
Power_On_Hours: 41,255
≈ 4.7 years running
Typical HDD reliability curve:
0–20k hours → very safe
20–40k hours → normal
40–60k hours → rising failures
60k+ hours → high failure probability
You just entered the rising failure window.
One interesting thing in your SMART dataThese values are very high:
Start_Stop_Count 46199
Power_Cycle_Count 35416
This suggests the disk was likely used in:
a NAS with aggressive spindown
an external USB enclosure
or a system that powers on/off often
Frequent spin-ups cause mechanical wear.
My honest verdictFactor Status
Surface health
PerfectBad sectors
NoneError logs
NoneTemperature
GoodAge
OldSpin cycles
High Safe to keep using, but not a drive I'd trust without backups.