Schlecht für die chronologische Sortierung.
Gebe ich dir Recht.. "22_03_01 Gehaltsabrechnung" ist besser
")

Ab sofort steht euch hier im Forum die neue Add-on Verwaltung zur Verfügung – eine zentrale Plattform für alles rund um Erweiterungen und Add-ons für den DSM.
Damit haben wir einen Ort, an dem Lösungen von Nutzern mit der Community geteilt werden können. Über die Team Funktion können Projekte auch gemeinsam gepflegt werden.
Was die Add-on Verwaltung kann und wie es funktioniert findet Ihr hier
Schlecht für die chronologische Sortierung.
Für was sollte das notwendig sein? Wenn du das inotify Paket (Drittanbieter) aus dem Store installierst und das neueste synOCR drauf hast, dann starten die Scanvorgänge vollautomatisch.Gibt es eigentlich einen http Befehl um den Scanvorgang zu starten? Dann könnte man sich die Logins auf die DS ersparen.
Über das GUI werden wir das wohl nicht so einfach umgesetzt bekommen. Ich denke da braucht es eine YAML-Datei.Ich wollte mich erstmal an die GUI wagen
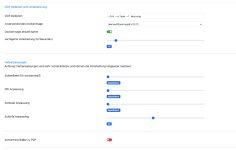
@Gthorsten1. Wenn ich ein bestimmten Dokumententyp von der Stuttgarter scanne, wird das Datum nicht erkannt und das Scandatum als Fallback verwendet (siehe IMG_0618). Markiere ich das Datum kann ich korrekt kopieren. OCR hat die Zeichen korrekt erkannt.
2025-04-24 22:51:52,780 - Line from File: Stuttgart, 15.4.2025
2025-04-24 22:51:52,780 - finish searching for alphanumerical and numerical dates......
2025-04-24 22:51:52,780 - found 0 dates
2025-04-24 22:51:52,781 - no dates found
2025-04-24 22:51:52,781 - found date None
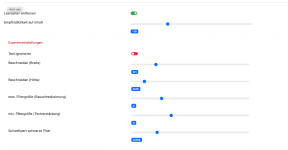
2025-04-24 22:51:52,781 - Date scanning endedIn der ersten Beta, wo die Farbanpassung implementiert wurde, war diese standardmäßig aktiviert. Bitte kontrolliere das mal in der GUI und dekativiere sie bei Bedarf.2. Wenn ich einen Scan vor der Verarbeitung durch dynOCR betrachte, ist die Qualität sehr gut und es treten so gut wie keine Störungen rund um den Text auf. Nach der Verarbeitung durch synOCR nimmt die Qualität deutlich ab und es rauscht stärker (siehe IMG_0616 und IMG_0617)
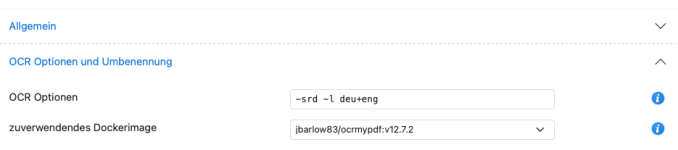
Hej,Warum ist dir der PDF Standard 1.4 so entscheidend?
@geimist gerade die Nachricht bekommen. Werde ich mir ansehen@Gthorsten
Das Datum wird in der Tat nicht gefunden.
Code:2025-04-24 22:51:52,780 - Line from File: Stuttgart, 15.4.2025 2025-04-24 22:51:52,780 - finish searching for alphanumerical and numerical dates...... 2025-04-24 22:51:52,780 - found 0 dates 2025-04-24 22:51:52,781 - no dates found 2025-04-24 22:51:52,781 - found date None 2025-04-24 22:51:52,781 - Date scanning ended
In der ersten Beta, wo die Farbanpassung implementiert wurde, war diese standardmäßig aktiviert. Bitte kontrolliere das mal in der GUI und dekativiere sie bei Bedarf.


Wenn du das Forum hilfreich findest oder uns unterstützen möchtest, dann gib uns doch einfach einen Kaffee aus.
Als Dankeschön schalten wir deinen Account werbefrei.