
- Registriert
- 22. Okt. 2018
- Beiträge
- 2.905
- Reaktionspunkte
- 343
- Punkte
- 123
Ja, ich weiß, dass es schon mehrere Threads dazu gibt, aber meine Fragen wurden nicht bantwortet.
Gestern kurz nachdem ich auf Arbeit bin (etwa 0,5 Stunden danach) tauchte diese Meldung auf (laut Log), was ich dann abends bemerkte, als das NAS mich anpiepte. (eine Mail wäre versendet worden, aber da gibt es grade irgendein Problem, drum anschließend noch die Meldung dass die Mail nicht rausging)
Die Platte ist einfach so spurlos verschwunden, auch aus der RAID-Config raus (DS nicht runtergefahren/neugestartet).
Vorallem das Letzte darf doch garnicht passieren?
Hatte sie abends kurz am PC, aber keine Probleme gefunden und als sie wieder im NAS steckte, wird sie nun angezeigt, aber so, wie eine neue noch nicht zugewiesene Platte.
Ich hatte vorh Jahren mal getestet, als das NAS noch neu war und wo ich noch bissl gefahrlos rumspielen konnte, wie das so läuft, wenn eine Platte "verschwindet" und wie das mit dem "reparieren" abläuft.
Da wurde aber die "Platte" mit Fehlermeldung noch im System angezeigt und ich konnte eine andere Platte dafür einsetzen und damit reparieren/ersetzen.
Jetzt ist die (alte) Platte nicht im RAID. Es gibt zwar einen reparieren Knopf, aber was macht der nun jetzt?
Eigentlich würde ich auch ja gern wissen, warum es passiert ist, denn wie soll man sonst rausbekommen, ob/wann es nochmal passieren kann.
Benachrichtigungen / Protokol-Center / synosys.log:
Storage Pool [1] was degrade [2/3], please repair it.
bzw.
Zustand von Speicherpool XYZ hat sich verschlechtert.
SpeicherManager / disklog*.csv:
garnichts, außer dann Abends die Meldung über entfernen und anstecken der Platte, wo ich sie mir angesehn hatte, aber vormitags und seit Tagen kein Eintrag
disk.log und kern.log (vollständig im Anhang ... früh der Fehler und Abends, als ich sie zum Testen rausgenommen hatte)
2021-07-27T10:07:09+02:00 ************* kernel: [632330.728088] ata1: device unplugged sstatus 0x0
2021-07-27T10:07:09+02:00 ************* kernel: [632330.743182] ata1.00: exception Emask 0x50 SAct 0x300 SErr 0x4090800 action 0xe frozen
2021-07-27T10:07:09+02:00 ************* kernel: [632330.752064] ata1.00: irq_stat 0x00400040, connection status changed
2021-07-27T10:07:09+02:00 ************* kernel: [632330.759196] ata1: SError: { HostInt PHYRdyChg 10B8B DevExch }
2021-07-27T10:07:09+02:00 ************* kernel: [632330.765715] ata1.00: failed command: READ FPDMA QUEUED
2021-07-27T10:07:09+02:00 ************* kernel: [632330.771597] ata1.00: cmd 60/80:40:e0:3a:23/00:00:bc:00:00/40 tag 8 ncq 65536 in
2021-07-27T10:07:09+02:00 ************* kernel: [632330.788864] ata1.00: status: { DRDY }
2021-07-27T10:07:09+02:00 ************* kernel: [632330.793045] ata1.00: failed command: READ FPDMA QUEUED
2021-07-27T10:07:09+02:00 ************* kernel: [632330.798882] ata1.00: cmd 60/20:48:20:8f:01/00:00:16:00:00/40 tag 9 ncq 16384 in
2021-07-27T10:07:09+02:00 ************* kernel: [632330.816149] ata1.00: status: { DRDY }
2021-07-27T10:07:09+02:00 ************* kernel: [632330.820340] ata1: hard resetting link
2021-07-27T10:07:15+02:00 ************* kernel: [632337.060277] ata1: link is slow to respond, please be patient (ready=0)
2021-07-27T10:07:19+02:00 ************* kernel: [632341.008379] ata1: softreset failed (device not ready)
PS: Jetzt wo ich die Werte StartStop und PowerOn im SMART seh, werde ich den Sleep wohl abchalten ... lohnt ja nicht wirklich. (Stromsparen und ab und an mal bissl weniger Wärme im System)
- aktuelles NAS+Platten ist jetzt knapp 2,5 Jahre alt, wobei die ProblemPlatte erst 1,5 Jahre läuft (3x 8TB WD RED + 1x 8TB USB für Backup)
- und bisher lief alles eigentlich problemlos, auch S.M.A.R.T-Tests und Co. hatten auch noch nichts gemeldet, außer
- mehrmals Stromausfall, sowie rausgeflogene Sicherung
- vor etwa einem Monat war die DS zur Sicherheit runtergefahren - SSD im Cache war zu warm geworden (70°C), da unten die Zuluft teilweise nicht mehr ganz offen war
- das NAS läuft eigentlich durch (nur in den zu seltenen Momenten wo mal länger nichts auf der HDD rumkramt, gehen die HDDs schlafen)
- ich hab aktuell kein Vollbackup (nur das Wichtigte auf USB)
aber da ich jetzt die Wahl hab, wüsste ich gern, ob was "garantiert" kaputt geht, wenn ich auf [Reparieren] klicke, oder ob ich mir doch noch vorher eine zusätzliche oder größere Backupplatte besorge- wie gesagt, im RAID fehlt die Platte komplett (sie wird aktuell als "nicht zugeordnet" angezeigt) und damit seh ich jetzt nichts, wo ich "Diese ersetzen" sagen könnte
Gestern kurz nachdem ich auf Arbeit bin (etwa 0,5 Stunden danach) tauchte diese Meldung auf (laut Log), was ich dann abends bemerkte, als das NAS mich anpiepte. (eine Mail wäre versendet worden, aber da gibt es grade irgendein Problem, drum anschließend noch die Meldung dass die Mail nicht rausging)
Die Platte ist einfach so spurlos verschwunden, auch aus der RAID-Config raus (DS nicht runtergefahren/neugestartet).
Vorallem das Letzte darf doch garnicht passieren?
Hatte sie abends kurz am PC, aber keine Probleme gefunden und als sie wieder im NAS steckte, wird sie nun angezeigt, aber so, wie eine neue noch nicht zugewiesene Platte.
Ich hatte vorh Jahren mal getestet, als das NAS noch neu war und wo ich noch bissl gefahrlos rumspielen konnte, wie das so läuft, wenn eine Platte "verschwindet" und wie das mit dem "reparieren" abläuft.
Da wurde aber die "Platte" mit Fehlermeldung noch im System angezeigt und ich konnte eine andere Platte dafür einsetzen und damit reparieren/ersetzen.
Jetzt ist die (alte) Platte nicht im RAID. Es gibt zwar einen reparieren Knopf, aber was macht der nun jetzt?
- repariert der bloß mit den beiden verbleibenden Platten? (danach wäre ja alles futsch, außer der macht ein RAID 0 daraus)
- oder wird die neue Platte (eigentlich die Alte, aber die wird ja beim Einbinden eh neu überschieben) angefordert, wenn ich auf reparieren klicke
- oder muß ich erst die neue Platte zum RAID hinzufügen und dann reparieren
Eigentlich würde ich auch ja gern wissen, warum es passiert ist, denn wie soll man sonst rausbekommen, ob/wann es nochmal passieren kann.
Benachrichtigungen / Protokol-Center / synosys.log:
Storage Pool [1] was degrade [2/3], please repair it.
bzw.
Zustand von Speicherpool XYZ hat sich verschlechtert.
SpeicherManager / disklog*.csv:
garnichts, außer dann Abends die Meldung über entfernen und anstecken der Platte, wo ich sie mir angesehn hatte, aber vormitags und seit Tagen kein Eintrag
disk.log und kern.log (vollständig im Anhang ... früh der Fehler und Abends, als ich sie zum Testen rausgenommen hatte)
2021-07-27T10:07:09+02:00 ************* kernel: [632330.728088] ata1: device unplugged sstatus 0x0
2021-07-27T10:07:09+02:00 ************* kernel: [632330.743182] ata1.00: exception Emask 0x50 SAct 0x300 SErr 0x4090800 action 0xe frozen
2021-07-27T10:07:09+02:00 ************* kernel: [632330.752064] ata1.00: irq_stat 0x00400040, connection status changed
2021-07-27T10:07:09+02:00 ************* kernel: [632330.759196] ata1: SError: { HostInt PHYRdyChg 10B8B DevExch }
2021-07-27T10:07:09+02:00 ************* kernel: [632330.765715] ata1.00: failed command: READ FPDMA QUEUED
2021-07-27T10:07:09+02:00 ************* kernel: [632330.771597] ata1.00: cmd 60/80:40:e0:3a:23/00:00:bc:00:00/40 tag 8 ncq 65536 in
2021-07-27T10:07:09+02:00 ************* kernel: [632330.788864] ata1.00: status: { DRDY }
2021-07-27T10:07:09+02:00 ************* kernel: [632330.793045] ata1.00: failed command: READ FPDMA QUEUED
2021-07-27T10:07:09+02:00 ************* kernel: [632330.798882] ata1.00: cmd 60/20:48:20:8f:01/00:00:16:00:00/40 tag 9 ncq 16384 in
2021-07-27T10:07:09+02:00 ************* kernel: [632330.816149] ata1.00: status: { DRDY }
2021-07-27T10:07:09+02:00 ************* kernel: [632330.820340] ata1: hard resetting link
2021-07-27T10:07:15+02:00 ************* kernel: [632337.060277] ata1: link is slow to respond, please be patient (ready=0)
2021-07-27T10:07:19+02:00 ************* kernel: [632341.008379] ata1: softreset failed (device not ready)
PS: Jetzt wo ich die Werte StartStop und PowerOn im SMART seh, werde ich den Sleep wohl abchalten ... lohnt ja nicht wirklich. (Stromsparen und ab und an mal bissl weniger Wärme im System)
Anhänge
-
 Benachrichtigungen.png160,6 KB · Aufrufe: 8
Benachrichtigungen.png160,6 KB · Aufrufe: 8 -
disk.log (und kern.log).log.txt15,1 KB · Aufrufe: 0
-
Protokoll-Center.csv.txt97 Bytes · Aufrufe: 0
-
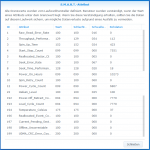 SMART.png48,5 KB · Aufrufe: 8
SMART.png48,5 KB · Aufrufe: 8 -
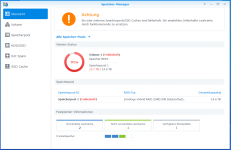 Speicher-Manager - 1 Übersicht.png55,3 KB · Aufrufe: 8
Speicher-Manager - 1 Übersicht.png55,3 KB · Aufrufe: 8 -
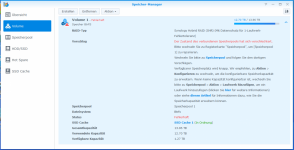 Speicher-Manager - 2 Volume.png448,3 KB · Aufrufe: 6
Speicher-Manager - 2 Volume.png448,3 KB · Aufrufe: 6 -
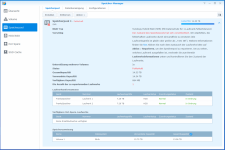 Speicher-Manager - 3 Speicherpool.png685,4 KB · Aufrufe: 6
Speicher-Manager - 3 Speicherpool.png685,4 KB · Aufrufe: 6 -
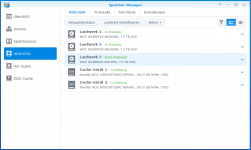 Speicher-Manager - 4 HDD.png48,1 KB · Aufrufe: 6
Speicher-Manager - 4 HDD.png48,1 KB · Aufrufe: 6 -
Speicher-Manager (disklog_2021-7-28-2 25 28).csv.txt2 KB · Aufrufe: 1
-
synosys.log.txt86 Bytes · Aufrufe: 0
 . (es sind aber auch sehr sehr viele kleine Dateien dabei)
. (es sind aber auch sehr sehr viele kleine Dateien dabei)





