- Mitglied seit
- 29. Okt 2009
- Beiträge
- 31
- Punkte für Reaktionen
- 0
- Punkte
- 0
Hi mir ist soeben das Volume 1 abgestürzt. Es ist eine Ds 209+II un die Platte ist eine 1000GB Samsung SpinPoint F1 HD103UJ im Basic betrieb. Habe gerade auf eine Externe Festplatte ein Backup gezogen und dann ist sie abgestürzt.
Lesenden Zugriff habe ich noch bin auch schon am Backuppen.
Im Protokoll kamen diese Meldungen:
SMART test ergab Anormalen Status.
Die Datenträger Info sagt folgendes:
Auszug aus dem Log: (20:20:01 war der Crash)
Volume 2 ist noch intakt.
Wie soll ich nun weiter vorgehen?
Thx schonmal, Patrick
Lesenden Zugriff habe ich noch bin auch schon am Backuppen.
Im Protokoll kamen diese Meldungen:
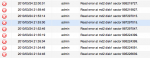
Error 2009/12/21 20:20:02 admin Read error at md2 disk1 sector 1502000199.
Error 2009/12/21 20:20:01 admin Internal disk [1] was defective.
SMART test ergab Anormalen Status.
Die Datenträger Info sagt folgendes:
Rich (BBCode):
* Dieses Volume kann nicht verwendet werden. Die Daten in diesem Volume wurden möglicherweise beschädigt. Versuchen Sie eine Sicherung Ihrer Daten, bevor Sie das Volume entfernen.
* Wegen der unvollständigen Datenkonsistenz auf diesem Volume ist es jetzt schreibgeschützt. Der Grund hierfür könnten fehlerhafte Sektoren auf der Festplatte sein. Sichern Sie die Daten auf dem Volume, bevor Sie es entfernen, und erstellen Sie ein neues Volume mit einer neuen Festplatte.
* Bitte entfernen Sie die Disk mit dem Status [Abgestürzt].
* Seien Sie beim Ausbau der Festplatte vorsichtig. Damit das System normal funktioniert, muss mindestens eine Festplatte den Status [Normal] oder [Initialisiert] haben.Auszug aus dem Log: (20:20:01 war der Crash)
Rich (BBCode):
Dec 21 20:17:52 kernel: ata1.00: exception Emask 0x0 SAct 0x1 SErr 0x0 action 0x
Dec 21 20:17:52 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:17:52 kernel: ata1.00: cmd 60/00:00:ef:bb:70/04:00:55:00:00/40 tag 0 n
Dec 21 20:17:52 kernel: res 41/40:6c:83:be:70/62:01:55:00:00/40 Emask 0
Dec 21 20:17:52 kernel: ata1.00: status: { DRDY ERR }
Dec 21 20:17:52 kernel: ata1.00: error: { UNC }
Dec 21 20:18:28 kernel: ata1.00: read unc at 1501999924
Dec 21 20:18:28 kernel: LBA 1501999924 start 6281415 end 1953520064
Dec 21 20:18:28 kernel: sda3 auto_remap 0
Dec 21 20:18:28 kernel: ata1.00: exception Emask 0x0 SAct 0x5 SErr 0x0 action 0x
Dec 21 20:18:28 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:18:28 kernel: ata1.00: cmd 60/00:00:47:b2:86/02:00:59:00:00/40 tag 0 n
Dec 21 20:18:28 kernel: res 41/40:13:34:b3:86/62:01:59:00:00/40 Emask 0
Dec 21 20:18:28 kernel: ata1.00: status: { DRDY ERR }
Dec 21 20:18:28 kernel: ata1.00: error: { UNC }
Dec 21 20:18:36 kernel: ata1.00: read unc at 1501999770
Dec 21 20:18:36 kernel: LBA 1501999770 start 6281415 end 1953520064
Dec 21 20:18:36 kernel: sda3 auto_remap 0
Dec 21 20:18:36 kernel: ata1.00: exception Emask 0x0 SAct 0x2 SErr 0x0 action 0x
Dec 21 20:18:36 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:18:36 kernel: ata1.00: cmd 60/00:08:47:b2:86/02:00:59:00:00/40 tag 1 n
Dec 21 20:18:36 kernel: res 41/40:ad:9a:b2:86/62:01:59:00:00/40 Emask 0
Dec 21 20:18:36 kernel: ata1.00: status: { DRDY ERR }
Dec 21 20:18:36 kernel: ata1.00: error: { UNC }
Dec 21 20:18:38 kernel: ata1.00: read unc at 1501999687
Dec 21 20:18:38 kernel: LBA 1501999687 start 6281415 end 1953520064
Dec 21 20:18:38 kernel: sda3 auto_remap 0
Dec 21 20:18:38 kernel: ata1.00: exception Emask 0x0 SAct 0x1 SErr 0x0 action 0x
Dec 21 20:18:38 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:18:38 kernel: ata1.00: cmd 60/00:00:47:b2:86/02:00:59:00:00/40 tag 0 n
Dec 21 20:18:38 kernel: res 41/40:00:47:b2:86/62:02:59:00:00/40 Emask 0
Dec 21 20:18:38 kernel: ata1.00: status: { DRDY ERR }
Dec 21 20:18:38 kernel: ata1.00: error: { UNC }
Dec 21 20:18:40 kernel: ata1.00: read unc at 1501999690
Dec 21 20:18:40 kernel: LBA 1501999690 start 6281415 end 1953520064
Dec 21 20:18:40 kernel: sda3 auto_remap 0
Dec 21 20:18:40 kernel: ata1.00: exception Emask 0x0 SAct 0x1 SErr 0x0 action 0x
- /var/log/messages 750/830 90%
Dec 21 20:18:44 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:18:44 kernel: ata1.00: cmd 60/00:00:47:b2:86/02:00:59:00:00/40 tag 0 ncq 262144 in
Dec 21 20:18:44 kernel: res 41/40:08:3f:b3:86/62:01:59:00:00/40 Emask 0x409 (media error) <F>
Dec 21 20:18:44 kernel: ata1.00: status: { DRDY ERR }
Dec 21 20:18:44 kernel: ata1.00: error: { UNC }
Dec 21 20:18:46 kernel: ata1.00: read unc at 1501999688
Dec 21 20:18:46 kernel: LBA 1501999688 start 6281415 end 1953520064
Dec 21 20:18:46 kernel: sda3 auto_remap 0
Dec 21 20:18:46 kernel: ata1.00: exception Emask 0x0 SAct 0x1 SErr 0x0 action 0x0
Dec 21 20:18:46 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:18:46 kernel: ata1.00: cmd 60/00:00:47:b2:86/02:00:59:00:00/40 tag 0 ncq 262144 in
Dec 21 20:18:46 kernel: res 41/40:ff:48:b2:86/62:01:59:00:00/40 Emask 0x409 (media error) <F>
Dec 21 20:18:46 kernel: ata1.00: status: { DRDY ERR }
Dec 21 20:18:46 kernel: ata1.00: error: { UNC }
Dec 21 20:18:46 kernel: Descriptor sense data with sense descriptors (in hex):
Dec 21 20:18:46 kernel: end_request: I/O error, dev sda, sector 1501999935
Dec 21 20:18:46 kernel: read error, md2, sda3 index [0], sector 1502000183 [raid1_end_read_request]
Dec 21 20:18:46 kernel: read error, md2, sda3 index [0], sector 1502000199 [raid1_end_read_request]
Dec 21 20:18:49 kernel: ata1.00: read unc at 1501999943
Dec 21 20:18:49 kernel: LBA 1501999943 start 6281415 end 1953520064
Dec 21 20:18:49 kernel: sda3 auto_remap 0
Dec 21 20:18:49 kernel: ata1.00: exception Emask 0x0 SAct 0x7 SErr 0x0 action 0x0
Dec 21 20:18:49 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:18:49 kernel: ata1.00: cmd 60/08:10:3f:b3:86/00:00:59:00:00/40 tag 2 ncq 4096 in
Dec 21 20:18:49 kernel: res 41/40:00:47:b3:86/00:00:59:00:00/40 Emask 0x409 (media error) <F>
Dec 21 20:18:49 kernel: ata1.00: status: { DRDY ERR }
Dec 21 20:18:49 kernel: ata1.00: error: { UNC }
Dec 21 20:18:53 scemd: modules/raid_data_volume_check.c:984 /volume1 state changes from 0 to 3.
Dec 21 20:19:03 scemd: SCEMD: read error at md2 disk 1 sector 1502000183
Dec 21 20:19:15 scheduler: scheduler.c (1596) Got signal. Die gracefully.
Dec 21 20:19:15 scheduler: scheduler.c (1614) rTorrent is killed.
Dec 21 20:19:19 kernel: ata1: failed to read log page 10h (errno=-5)
Dec 21 20:19:19 kernel: ata1.00: exception Emask 0x1 SAct 0x1f SErr 0x0 action 0x0
Dec 21 20:19:19 kernel: ata1.00: irq_stat 0x00060002, device error via SDB FIS
Dec 21 20:19:19 kernel: ata1.00: cmd 60/f8:00:4f:ee:85/00:00:59:00:00/40 tag 0 ncq 126976 in
Dec 21 20:19:19 kernel: res 50/00:00:af:6d:70/00:00:74:00:00/e0 Emask 0x1 (device error)
Dec 21 20:19:19 kernel: ata1.00: status: { DRDY }
Dec 21 20:19:19 kernel: ata1.00: cmd 60/08:08:47:ef:85/01:00:59:00:00/40 tag 1 ncq 135168 in
Dec 21 20:19:19 kernel: res 50/00:00:af:6d:70/00:00:74:00:00/e0 Emask 0x1 (device error)
Dec 21 20:19:19 kernel: ata1.00: status: { DRDY }
Dec 21 20:19:19 kernel: ata1.00: cmd 60/08:10:46:19:4c/00:00:00:00:00/40 tag 2 ncq 4096 in
Dec 21 20:19:19 kernel: res 50/00:00:af:6d:70/00:00:74:00:00/e0 Emask 0x1 (device error)
Dec 21 20:19:19 kernel: ata1.00: status: { DRDY }
Dec 21 20:19:19 kernel: ata1.00: cmd 60/00:18:4f:f0:85/04:00:59:00:00/40 tag 3 ncq 524288 in
Dec 21 20:19:19 kernel: res 50/00:00:af:6d:70/00:00:74:00:00/e0 Emask 0x1 (device error)
Dec 21 20:19:19 kernel: ata1.00: status: { DRDY }
Dec 21 20:19:19 kernel: ata1.00: cmd 61/08:20:17:90:01/00:00:00:00:00/40 tag 4 ncq 4096 out
Dec 21 20:19:19 kernel: res 50/00:00:af:6d:70/00:00:74:00:00/e0 Emask 0x1 (device error)
Dec 21 20:19:19 kernel: ata1.00: status: { DRDY }
Dec 21 20:19:19 kernel: ata1.00: failed to IDENTIFY (I/O error, err_mask=0x1)
Dec 21 20:19:19 kernel: ata1.00: revalidation failed (errno=-5)
Dec 21 20:19:19 kernel: ata1: failed to recover some devices, retrying in 2 secs
Dec 21 20:19:41 kernel: nfsd: last server has exited
Dec 21 20:19:41 kernel: nfsd: unexporting all filesystems
Dec 21 20:19:49 synorcd: hw_raytac.c (126) failed to open /dev/usb/hiddev5 (No such device).
Dec 21 20:19:55 exportfs[8727]: can't open /var/lib/nfs/rmtab for reading
Dec 21 20:20:01 scemd: SYNORemountCrashRaidRo(59) mount -o remount,ro /dev/md2 /volume1
Dec 21 20:20:01 scemd: ScemRefreshDiskLed(446)Disk 1 fail
Dec 21 20:20:02 scemd: SCEMD: read error at md2 disk 1 sector 1502000199
- /var/log/messages 830/830 100%Volume 2 ist noch intakt.
Wie soll ich nun weiter vorgehen?
Thx schonmal, Patrick
Zuletzt bearbeitet: