- Mitglied seit
- 15. Mai 2008
- Beiträge
- 21.900
- Punkte für Reaktionen
- 14
- Punkte
- 0
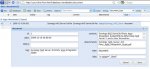
Nachdem das Thema Dokumenten Management (DMS) wieder einmal etwas gestresst worden ist, habe ich gedacht, dass wir im Winter-Camp-Workshop eine ExtJS-Anwendung zu diesem Thema entwickeln. Ich hatte ja schon hier eine einfache Datenbankanwendung für beliebige Datenbanktabellen vorgestellt und diese soll jetzt ein wenig in Richtung DMS erweitert werden.
Zum Gesamtkonzept:
- Die Anwendung ist nichts für unbedarfte Benutzer, weil sie wenig Vorkehrungen vor Falscheingaben haben wird
- Zunächst werden nur PDF-Dokumente verwaltet und diese müssen in einem 'durchsuchbaren' Format vorliegen, damit das Tool pdftotext auch an den Inhalt herankommen kann. Durchsuchbare PDFs werden von den meisten Scannern produziert bzw. können mit geeigneten Windows-Tools (Abbyy) hergestellt werden; grundsätzlich sind weitere Dateitypen denkbar und möglich
- Die Aufnahme neuer Dokumente wird zunächst manuell und einzeln abgewickelt; könnte später auch über einen Crawler geschehen
- Die Dokumente werden in einem Dokumenten-Verzeichnis abgelegt und ähnlich wie bei anderen Synology-Programme über einen Datenbankeintrag verwaltet. Je nach Dokumentenanzahl sollte man sich eine geeignete Hierarchie im Voraus überlegen, da die Pfade innerhalb der Datenbank nicht automatisch aktualisiert werden; könnte man später per Crawler ein wenig lockerer sehen
- Die Abfragen werden mit klassischem SQL-Where-Abfragen eingegeben; daher sollte man die Syntax für die Where-Klausel können bzw. lernen wollen. Die darunter operierende MySQL-Datenbank kennt spezielle Datenbank-Abfrage-Notationen für Volltext-Indizes; dies kann man auch einsetzen
Es ist notwendig, sich mit ExtJS, JavaScript, PHP und MySQL auseinandersetzen zu wollen ... es ist nicht notwendig, alles in den Skripte sofort und gleich zu verstehen.
Das Grundgerüst des hier vorgestellten DMS:
- Datenbankunterstützte DMS-Verwaltung, die einfach auf persönliche Wünsche hin angepasst werden kann
- Volltext-Recherche
- Supergeile ExtJS-GUI
- Lauffähig auf allen DS-Modellen, wo man per IPKG xpdf-Tools installieren kann
- Beliebige Verlinkung der Dokumente untereinander
- Beliebig viele Notizen pro Dokument mit Zeitangabe für eine Wiedervorlage
- Ausdruck von hübschen Übersichtslisten (auch von Teillisten, welche aus Abfragen resultieren)
Itari
Zum Gesamtkonzept:
- Die Anwendung ist nichts für unbedarfte Benutzer, weil sie wenig Vorkehrungen vor Falscheingaben haben wird
- Zunächst werden nur PDF-Dokumente verwaltet und diese müssen in einem 'durchsuchbaren' Format vorliegen, damit das Tool pdftotext auch an den Inhalt herankommen kann. Durchsuchbare PDFs werden von den meisten Scannern produziert bzw. können mit geeigneten Windows-Tools (Abbyy) hergestellt werden; grundsätzlich sind weitere Dateitypen denkbar und möglich
- Die Aufnahme neuer Dokumente wird zunächst manuell und einzeln abgewickelt; könnte später auch über einen Crawler geschehen
- Die Dokumente werden in einem Dokumenten-Verzeichnis abgelegt und ähnlich wie bei anderen Synology-Programme über einen Datenbankeintrag verwaltet. Je nach Dokumentenanzahl sollte man sich eine geeignete Hierarchie im Voraus überlegen, da die Pfade innerhalb der Datenbank nicht automatisch aktualisiert werden; könnte man später per Crawler ein wenig lockerer sehen
- Die Abfragen werden mit klassischem SQL-Where-Abfragen eingegeben; daher sollte man die Syntax für die Where-Klausel können bzw. lernen wollen. Die darunter operierende MySQL-Datenbank kennt spezielle Datenbank-Abfrage-Notationen für Volltext-Indizes; dies kann man auch einsetzen
Es ist notwendig, sich mit ExtJS, JavaScript, PHP und MySQL auseinandersetzen zu wollen ... es ist nicht notwendig, alles in den Skripte sofort und gleich zu verstehen.
Das Grundgerüst des hier vorgestellten DMS:
- Datenbankunterstützte DMS-Verwaltung, die einfach auf persönliche Wünsche hin angepasst werden kann
- Volltext-Recherche
- Supergeile ExtJS-GUI
- Lauffähig auf allen DS-Modellen, wo man per IPKG xpdf-Tools installieren kann
- Beliebige Verlinkung der Dokumente untereinander
- Beliebig viele Notizen pro Dokument mit Zeitangabe für eine Wiedervorlage
- Ausdruck von hübschen Übersichtslisten (auch von Teillisten, welche aus Abfragen resultieren)
Itari
Zuletzt bearbeitet:
")